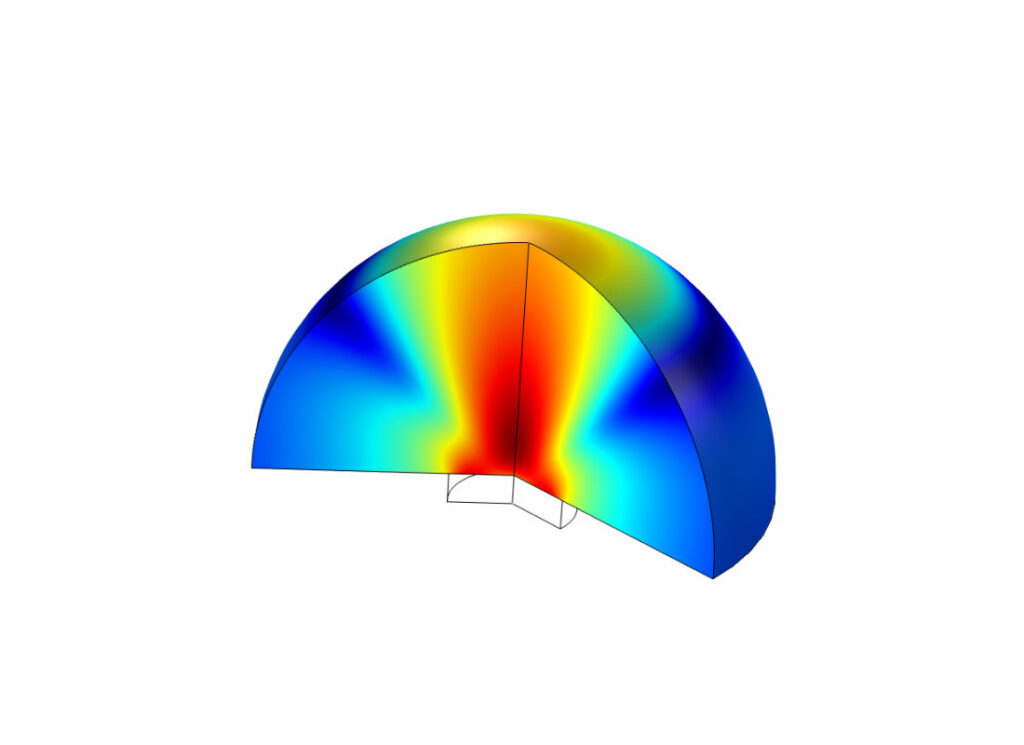
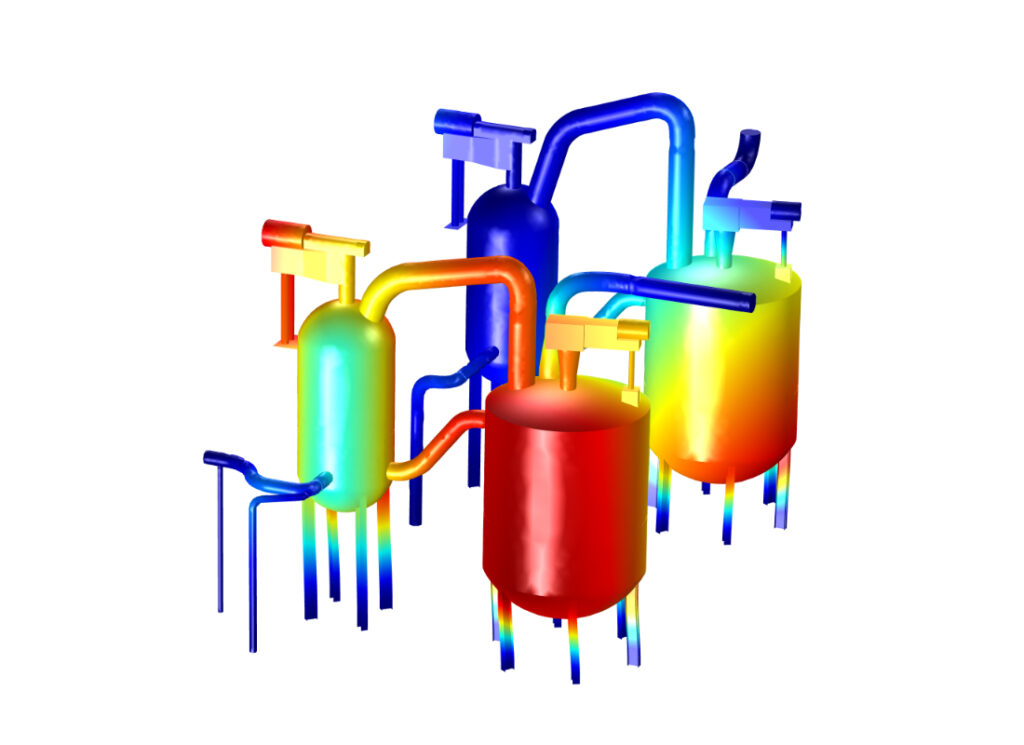
Why data processing and analysis matters
Modern systems produce vast amounts of data, but without context, it’s noise. Effective analysis transforms that data into clarity, reducing time-to-insight and driving smarter technical choices.
How we turn complex data into clear engineering insight
We combine signal processing, statistical analysis, and bespoke algorithms to extract meaningful patterns from complex datasets. Our methods bridge raw measurement and predictive modelling, feeding accurate insights into design, validation, and machine learning models.

Clarity
Understand what your data means and why it matters.
Speed
Automate and accelerate data workflows.
Integration
Feed validated data into models, dashboards, and digital twins.
See how Xi turns complex measurements into clear, decision ready insight for critical projects.
From raw monitoring data to simulation outputs, Xi Engineering Consultants uses rigorous processing, statistics and visualisation to reveal the patterns that matter. These projects show how our data work underpins better design choices, stronger business cases and clearer conversations with regulators and stakeholders.